
Die Suche nach „javascript seo“ fördert bei Google in 0,48 Sekunden etwa 148.000.000 Treffer zutage. Das ist ein erster Indikator dafür, wie wichtig das Thema JavaScript für Unternehmen ist – und auch dafür, wie viele Fragen und Unklarheiten es in diesem Bereich noch immer gibt.
Immer mehr Lösungen – auch für EinsteigerInnen
Wir sehen die steigende Bedeutung von JavaScript auch daran, dass die Frameworks immer mehr werden und die entsprechenden Libraries rasant anwachsen. Eine große Zahl an Lösungen stehen mittlerweile auch absoluten Einsteigern und Einsteigerinnen zur Verfügung, was die Hürden zur Nutzung zusätzlich senkt.
Der erste Kontaktpunkt ist meist eine Web App – doch was ist das eigentlich?
Nun, theoretisch ist eine Web App grob gesagt eine Website, die irgendeine Form der Interaktion zulässt. Und hier gehen die Fragen meistens schon los. Ist meine Seite eigentlich eine Web App – oder qualifiziert sie sich nicht dafür? Diese Definition passt nämlich überall und nirgendwo.

Spannend und oft verwirrend zugleich
Neben dieser grundlegenden Einschätzung gibt es noch zahlreiche andere Fragen, die beim Thema JavaScript immer wieder auftauchen. Die wichtigsten sind folgende:
1. Kann Google JavaScript? Googler sagen ja, viele SEOs sagen nein – und die Erfahrung lehrt, dass die Wahrheit irgendwo dazwischen liegt.
2. Wenn ja, in welchem Umfang? Naja, das ist die Frage aller Fragen.
3. Was bedeuten diese ganzen Begriffe überhaupt? Lesen, ausführen, „rendern” und viele andere Begrifflichkeiten sind unklar.
4. Wie steht es um andere Suchmaschinen? Oha – ein weites Feld mit sehr viel Graubereich, da gibt es einiges zu beackern.
5. Welche Technologen gibt es überhaupt? Von reinem JavaScript über fancy fertige Kits bis hin zu modernen neuen Tools, die den EntwicklerInnen die Arbeit leicht und dem oder der SEO das Leben schwer machen, gibt es vieles zu entdecken.
6. Was fange ich als SEO damit an? Erster Tipp: lern JavaScript, das kann nie schaden!
7. Was passiert eigentlich, wenn ich diesen Artikel mit meinem Browser aufrufe? Probier es doch einfach mal aus …
Siehst du den Wald vor lauter Bäumen noch?
Mit diesem Artikel wollen wir dir einen Einblick in die JavaScript-Welt geben und etwas Ordnung in diesem ganzen Wirrwarr schaffen. Wir werden also alle Fragen beantworten, die wir da gerade aufgeworfen haben – und noch einige mehr.
Wir möchten zum Beispiel auch ergründen, warum das Thema gerade jetzt so gehyped wird. Warum gibt es immer mehr Frameworks und Libraries? Und was ist eigentlich der Unterschied zwischen den beiden?
Und vor allem: Warum werden sie so gerne genutzt, obwohl es doch so ein schwieriges Thema mit so vielen Stolperfallen ist?

Unser Redaktionsplan
Inhalte im Internet & das World Wide Web
Im allgemeinen Sprachgebrauch bezeichnet der Begriff Internet in der Regel das World Wide Web, also das WWW. Dabei handelt es sich um ein Netzwerk aus Hypertext-Dokumenten, welches über das Internet abrufbar ist.
Das Internet ist quasi die darunterliegende Struktur mit viel mehr als nur dem WWW. Hier finden sich auch E-Mails, Gopher (na, wer kennt’s?) oder IRC (na wer kennt das auch?) und viele, viele andere Dinge.
Suchmaschinen haben meist das Ziel, Inhalte im WWW auffindbar zu machen. Spezielle Suchmaschinen finden auch andere Inhalte, das ist für unsere Zwecke aktuell aber eher nebensächlich. Der Abruf der Inhalte im WWW erfolgt über HTTP(S), also HyperText Transfer Protocol (Secure).
Dies regelt die Kommunikation zwischen Client und Server. Der Client fragt einen Inhalt an und der Server liefert diesen aus (bzw. beantwortet die Anfrage).
Welche Inhalte werden im WWW bereitgestellt?
Grundsätzlich findet man hier nahezu alles, was man so auf dem Computer speichern kann, also
Der Grundstein dafür sind HTML-Dokumente:
Ein simples HTML-Dokument, erreichbar unter http://beispiel.de
HTML-Dokumente haben dabei eine Besonderheit. Sie können auf andere Dokumente verweisen (referenzieren). Das funktioniert mit den allseits beliebten (Hyper-)Links. Diese sehen folgendermaßen aus: <a href=”https://www.beispiel.de/beispiel/”>Beispiel-Link</a>
Dabei steht das href für Hyperreference.
So kann man sich von einem Dokument zum nächsten bewegen und verschiedene Dokumente auf einer Website oder unterschiedlichen Websites besuchen. Es entsteht also ein Netzwerk aus mehreren Seiten.
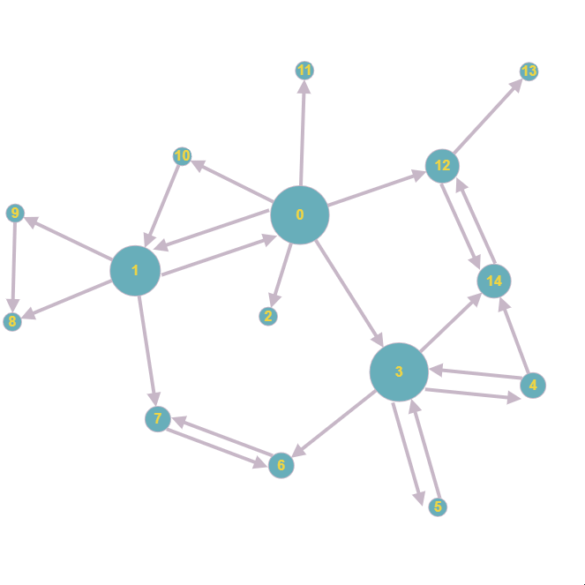
Ein sehr simples Netzwerk aus Dokumenten
Trotz der Einfachheit des dargestellten Netzwerkes kann es schon hier für einen Menschen schwer sein, das Dokument zu finden, nach dem er gerade sucht. Wie kommt man zum Beispiel am besten und ohne ewige Klickstrecken von Dokument 1 zu Dokument 5?
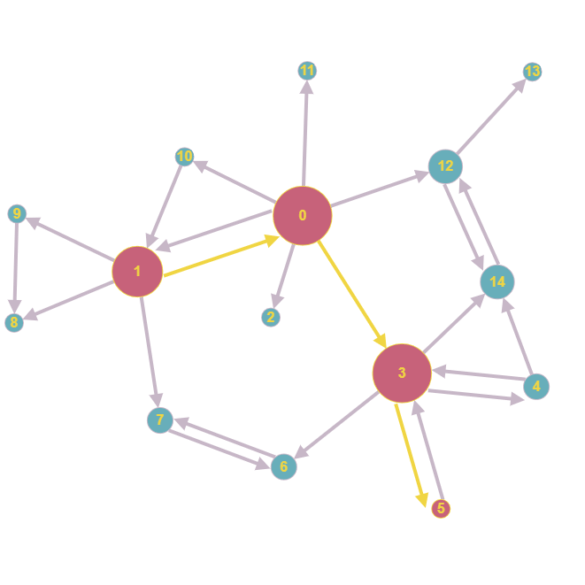
So geht der kürzeste Weg von Dokument 1 zu Dokument 5
Doch was passiert, wenn ich die Dokumente gar nicht selbst kenne? Und das ist oft der Fall, weil das WWW so riesig ist. Was passiert, wenn neue Dokumente hinzukommen?
In solchen Fällen nehmen die Suchmaschinen uns die Arbeit ab. Um möglichst alle Dokumente im WWW zu finden, nutzen sie die Kerneigenschaft der Dokumente: ihre Verbindung durch Hyperlinks.
Daher gilt: ohne Links kein WWW!
Das Crawling
Ein Webcrawler (auch „Spider“, oder „Bot“ genannt) ist ein Programm, das genau das tut:
1. Aufrufen eines Dokumentes
2. Extraktion aller Hyperlinks
3. Übermittlung der Hyperlinks an einen Scheduler
4. Weiter geht’s von vorn (Googlebot schläft nie)
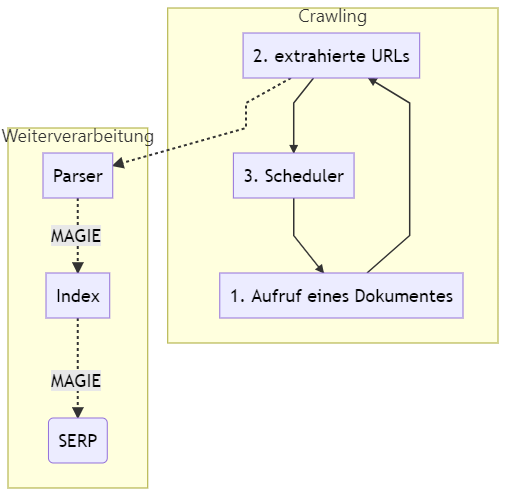
Stark vereinfachtes Schema
Der Einstieg passiert auf Dokument 0.
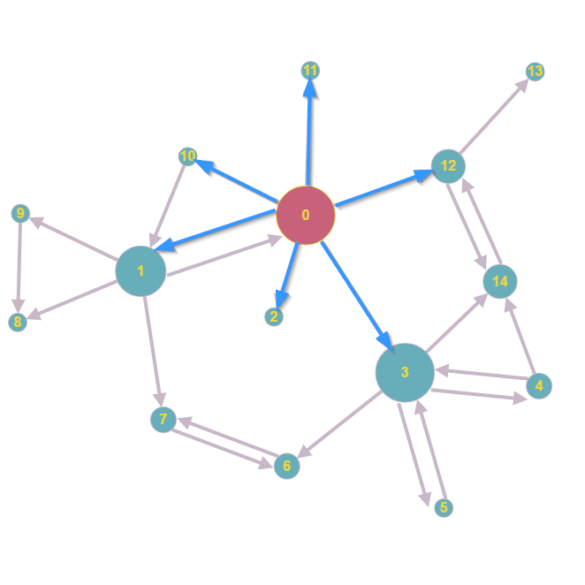
Beim Einstieg auf Dokument 0 findet der Crawler sechs Links zu neuen Dokumenten
Danach folgt der Aufruf der Dokumente 1, 2, 3, 10, 11 und 12. Nicht sonderlich schwierig, möchte man meinen.
Ein Webcrawler extrahiert Links zu Dokumenten im Web und bereitet diese auf. Sein Ziel ist es, weitere Dokumente zu finden.
Damit ist der erste und wichtigste Punkt im gesamten Kontext schon gefunden: scheitert das Crawling, entfallen alle weiteren Schritte der Verarbeitung! Das Crawling ist also essenziell.
Stolperfallen
Das wird gecrawlt
Gehen wir davon aus, dass alles stimmt, was der Mann von Google da sagt (auch wenn wir wissen, dass Google bedeutend mehr URLs folgt, als nur den hrefs). Hier leben wir einmal kurz im Google-Idealzustand. Was kann nun alles schiefgehen?
Bedenke: es ist ein Computerprogramm, das versucht, den Link aus dem Quelltext zu extrahieren. Diesem Vorgehen liegen mindestens zwei recht komplexe Annahmen zugrunde:
1. Ein Link ist eine URL, die in einem HTML-Dokument in einem <a> Tag als href referenziert wird
2. Der Ersteller des Dokuments weiß das und hält sich an die bekannten Standards
Again: Wenn man hier gegen die Vorgaben verstößt, sieht man schon alt aus.
Klassische Fehler:

Im Quelltext der Website steht ein JavaScript – dieses fragt die Navigationsstruktur bei einem Service an und erstellt sie dann dynamisch
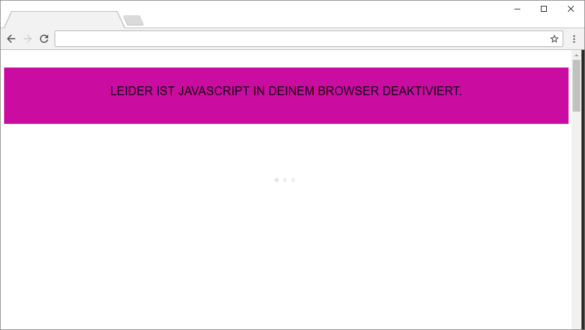
Wenn kein JavaScript ausgeführt wird, wird keine Navigation erstellt
Crawling und JavaScript
Problematisch wird es, wenn Links erst durch die Ausführung von JavaScript erkennbar werden. Denn diese Ausführung ist nicht nur ressourcenintensiv, sondern auch fehleranfällig und komplex.
Beispiel
Ein HTML-Dokument funktioniert auch ohne Markup:
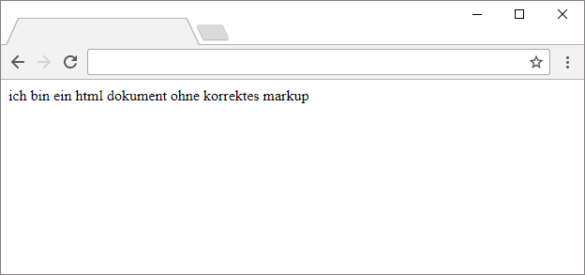
Auch ohne Markup kann ein HTML-Dokument funktionieren
Anmerkung: Das ist ein Extrembeispiel! Eine korrekte Syntax ist immer noch ein wichtiges Kriterium für gut funktionierende Websites!
Aber ein fehlendes ; kann ein komplettes Skript unbrauchbar machen. Gemäß dem oben definierten Konzept liest der Crawler lediglich die Inhalte des HTML-Quelltextes und extrahiert die Links.
Nehmen wir folgendes Dokument an:
<html>
<head>
<meta charset=”utf-8″ />
<script>
var eins = “<a href=’http://www.beispiel.de/”;
var zwei = “beispiel/’>Link zu Beispiel”;
var drei = “.de</a>”;
</script>
</head>
<body>
<h1>testdokument</h1>
<script>
document.write(eins + zwei + drei);
</script>
</body>
</html>
Rufe ich das Dokument im Webbrowser auf, so sehe ich, dass alles funktioniert, wie es soll:
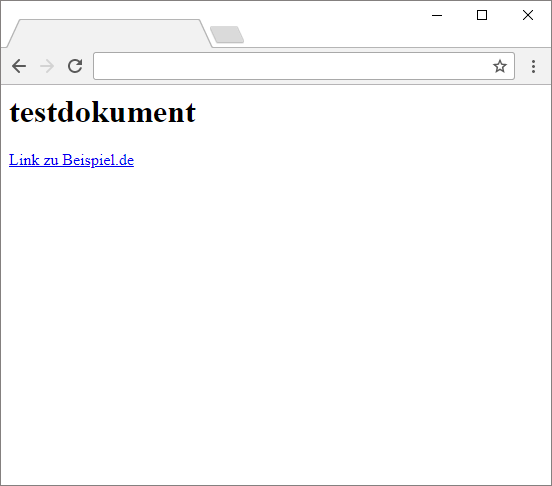
So soll es sein
Ein Crawler sieht bei Abruf des Dokumentes folgendes:
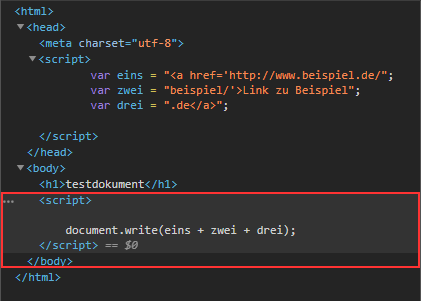
An der Stelle, an der wir den Link erwarten, sieht der Crawler lediglich das Skript
Hier endet die Arbeit für den Crawler. Erst, wenn er die Fähigkeit erhält, das JavaScript im HTML-Dokument auszuführen, kann er den Link entdecken und ihm folgen:
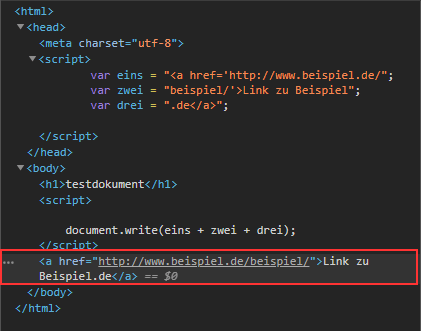
Ist der Crawler in der Lage, JavaScript auszuführen, so kann er den Link sehen
Und jetzt wird es haarig:
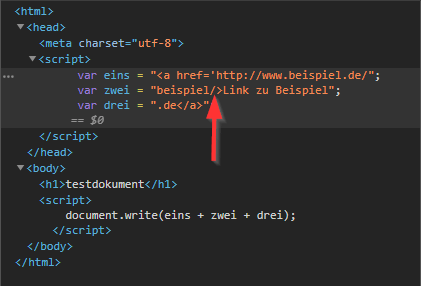
Ist das Skript nur minimal fehlerhaft, kann der Link nicht mehr generiert werden
Dieses Script ist mehr als simpel und diese und ähnliche Ausnahmen treten im WWW durchaus häufig auf.
Folgen für den Crawler
Die ProgrammiererInnen des Crawlers versuchen, möglichst alle bekannten und möglichen Ausnahmen abzufangen. Daher ruft der Googelbot alles auf, was in irgendeiner Form an eine URL erinnert (auch außerhalb von <a href=””>). Doch die Verarbeitung der Dokumente gestaltet sich deutlich schwieriger.
Folgen für uns als SEOs
Daraus schließen wir: Wer sicherstellen will, dass eine URL gecrawlt wird, stellt sie als HTML-Link zur Verfügung.
Doch wenn es bei einfachen Links schon so viele Probleme geben kann, wie sieht es dann erst bei komplexen Inhalten aus?
Was kannst du tun? Wie kannst du analysieren? Was musst du ändern? Oh Gott, wo fängst du an?

Einen Moment Geduld
Crawler Steuerung
Es ist für dich extrem wichtig, den Crawler richtig zu steuern, bzw. nicht auf Irrwege zu leiten. Das geht folgendermaßen:
Die robots.txt
Jede Website sollte eine haben. Sie regelt, welche Seitenbereiche vom Crawler besucht werden dürfen – und welche nicht. Sie spricht jedoch nur eine Empfehlung aus. Der Googlebot hält sich daran, aber der Bot vom Internet Archive zum Beispiel nicht. Sie hält also die meisten Bots davon ab, die Inhalte aufzurufen – sie bietet aber keinen Indexierungsschutz. Der Einfachheit halber solltest du komplizierte Regeln wo es geht vermeiden.
Ein Beispiel für eine robots.txt wäre die folgende:
User-agent: *
Disallow: /nicht-crawlen/
Die Meta-Angaben
Die Meta-Angaben stehen im Quelltext von HTML-Dokumenten und sehen zum Beispiel so aus:
<html>
<head>
<meta name=”robots” content=”index, follow”>
[…]
</head>
[…]
</html>
Für den Crawler sind vor allem die Angaben „follow“ und „nofollow“ wichtig. Sie geben an, ob den ausgehenden Links des Dokuments gefolgt werden soll.
Außerdem interessiert sich der Crawler für die Angaben „Index“ und „Noindex“. Diese sind für die spätere Verarbeitung entscheidend.
Der Unterschied zur robots.txt ist, dass das Dokument beim Einsatz von „nofollow“ zur Sackgasse wird. Bei der Sperrung mittels robots.txt kann weitreichender ausgeschlossen werden.
Die komplexen Block-Strategien
Komplett aussperren kannst du Crawler z. B. durch IP-Blockaden, Login-Formulare (hier genügt schon eine basic http authentication).
Suchmaschinen, allen voran Google, versuchen stets nachzuvollziehen, wie ein echter Nutzer bzw. einer Nutzerin eine Website „erlebt“. Um dies zu erreichen, werden die Seiten für die interne Verarbeitung mittlerweile gerendert, also genau so dargestellt, wie wir als Menschen sie im Browser sehen würden.
Dass das Thema Rendering aktuell und wichtig ist, zeigen auch wiederholt Aussagen von Google-MitarbeiterInnen:
Zeit, sich einmal mit der Frage zu befassen: Wie stellt ein Browser Websites für uns dar?
Du wirst überrascht sein, wieviel Arbeit ein moderner Browser verrichten muss.
HTML
Der Browser fordert das Dokument an, das er anzeigen soll. Entweder, weil du die URL des Dokuments eingegeben hast, oder weil du auf ein Suchergebnis geklickt hast.
Der Browser sagt zum Sever „gib mir bitte das Dokument ‘artikel.html’.“
Und der Server antwortet im besten Fall mit einem positiven Bescheid auf den Antrag des Browsers und schickt das angeforderte Dokument gleich mit.
Der Browser muss dann dieses Dokument lesen, verarbeiten, in eine für dich brauchbare Version übersetzen und diese dann darstellen. Das sieht dann in etwa so aus:
Der Browser stellt das HTML Dokument dar
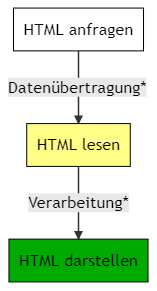
Der Prozess stark vereinfacht
HTML + CSS
Diese Ansicht ist aber wenig schön und kaum individuell. Cascading Style Sheets (CSS) übernehmen die Gestaltung des HTML-Dokumentes. Sie sind weitestgehend für das Aussehen moderner Websites verantwortlich. CSS geben dem Browser Regeln vor, nach denen er Elemente anordnet (Layout) und sie darstellt (Form, Farbe, Größe). Seit CSS3 sind sogar umfassende Animationen und Effekte möglich.
Um diese Regeln anwenden zu können, müssen zwei grundlegende Bedingungen erfüllt sein:
1. Der Browser muss die Regeln kennen
2. Der Browser muss die Elemente kennen, auf die er die Regeln anwenden soll
Das klingt trivial, stellt uns jedoch noch vor Herausforderungen.
Wir senden dem Browser neben unserer HTML-Datei noch eine CSS-Datei. Aus dieser kann er die Regeln herauslesen, die er braucht, um die Seite ansprechend und schön darzustellen.
Das bedeutet nun, dass der Browser zwei Anfragen an unseren Webserver senden muss. Ja, es gibt auch die Möglichkeit das CSS direkt im HTML unterzubringen. Wir halten uns der Einfachheit halber erst einmal an die goldene Regel Form und Inhalt voneinander zu trennen.
Und der Server antwortet wieder mit einem positiven Bescheid auf den Antrag des Browsers und schickt die Dokumente zurück.
Der Browser muss dann dieses Dokument lesen, verarbeiten, in eine für dich brauchbare Version übersetzen. Dann muss er die Regeln aus dem CSS lesen, verarbeiten, die zugehörigen Elemente im HTML-Dokument ausfindig machen und diese dann entsprechend gestalten. Bereits hier können wir beeinflussen, wie schnell der Browser die Darstellungsregeln anwenden kann.
Das Ergebnis sieht dann in etwa so aus:
Die HTML-Seite mit angewendeten CSS-Regeln – schick
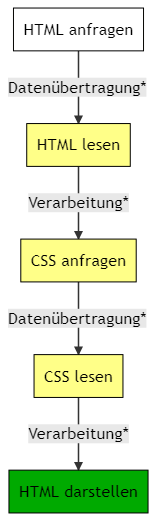
Der Prozess jetzt, immer noch stark vereinfacht
Experten-Einschub
Wenn man sich mit Webentwicklern unterhält, mag der Prozess oben etwas zu einfach sein.
Was der Browser im Schritt „Verarbeitung“ tut ist kurz gefasst folgendes:
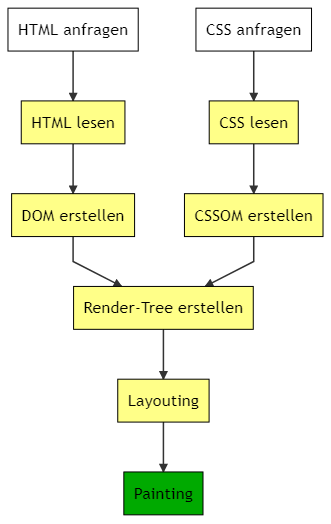
Der Darstellungsprozess – immer noch vereinfacht, aber etwas genauer
HTML + CSS + JS
Jetzt kommt JavaScript ins Spiel.
Wir möchten unseren Besuchern und Besucherinnen noch ein paar Usability-Gimmicks präsentieren. Wir wollen auch messen, wie viele BesucherInnen unsere Webseite hat. Und wir müssen ein paar rechtliche Vorschriften einhalte.
Für all diese Zwecke nutzen wir JavaScript. Und hier wird es verrückt.
Die Idee hinter JavaScript war und ist folgende: Der Browser führt kleine Programme aus, welche die Elemente, die er für uns darstellt, beeinflussen. So färbt er zum Beispiel ein Eingabefeld rot, wenn die Eingabe nicht der Erwartung entspricht. Oder er schreibt die aktuelle Uhrzeit in einen dafür vorgesehenen Bereich.
Damit der Browser das tun kann, müssen wieder eine Reihe von Voraussetzungen erfüllt sein:
1. Er muss das HTML-Dokument kennen
2. Er muss die CSS-Regeln kennen, um die Elemente korrekt darzustellen
3. Er muss das Programm (Skript) kennen, das er ausführen muss
4. Er muss weiterhin wissen, auf welches Element sich das Programm auswirkt
5. Er muss unter Umständen die Darstellung der Elemente aus 1. und 2.wieder anpassen
Für uns sieht das Ergebnis im ersten Moment nicht anders aus:
Die HTML-Seite mit angewendeten CSS-Regeln und JavaScript
Der Prozess dahinter verkompliziert sich jedoch ein wenig. Da der Browser sein Ziel möglichst schnell erreichen möchte, arbeitet er verschiedene Schritte parallel ab. So kann er zum Beispiel bereits anfangen, das HTML darzustellen, sobald er alle CSS Regeln kennt.
Wird ein JavaScript geladen, hält er den Prozess jedoch an. Der Browser weiß nicht, ob er eines der Elemente, die er darstellen möchte, verändern muss und wartet daher darauf, das Skript auszuführen.
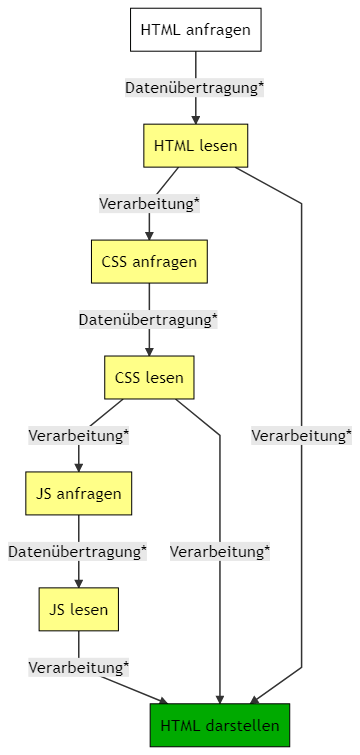
Der vollständige (stark reduzierte) Prozess mit HTML, CSS und JS
An allen mit * markierten Stellen kann etwas schief gehen. Im letzten Artikel haben wir bereits Beispiele gesehen, wie etwas schief gehen kann. Beim HTML ist er noch extrem tolerant, beim CSS kann es unschön werden, aber beim JS wird’s hakelig.
Experten-Einschub
JavaScript hat in der Regel die Aufgabe, die Objekte im DOM oder im CSSOM zu manipulieren. Daher wird der gesamte Darstellungsprozess gestoppt, sobald ein JavaScript ins Spiel kommt.
JavaScript blockiert das DOM (sofern wir nicht explizit dafür sorgen, dass sie dies nicht tun).
JavaScript kann erst ausgeführt werden, wenn das CSSOM fertig erstellt wurde.
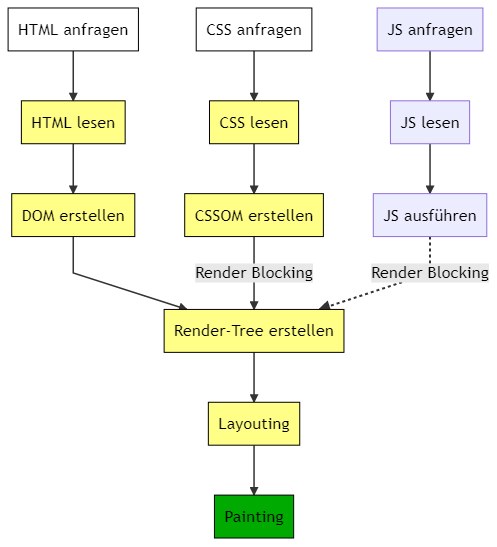
Der vollständige (stark reduzierte) Prozess mit HTML, CSS und JS
Erste Learnings
Hier bieten sich die ersten Stolpersteine für unsere JavaScript Website.
Da wir unsere Seite gut optimieren möchten, müssen wir dafür sorgen, dass sie schnell erstellt werden kann.
Warum? Ganz einfach, unsere Besucher und Besucherinnen wollen nicht ewig warten, bis die Seite fertig geladen ist. Das weiß auch Google. Und Google wartet auch nicht ewig, bis unsere Seite fertig geladen ist, wenn es sie crawlt.
Die ersten Maßnahmen, um unsere Seite etwas SEO-sicherer zu gestalten, sind daher:
1. Wir rufen JavaScript möglichst spät auf, um die Erstellung des CSSOM abzuwarten. Das bedeutet auch, dass CSS-Dateien immer vor JavaScript referenziert werden.
2. Wir laden so wenige JavaScript-Dateien wie möglich, da jeder Ladevorgang alle weiteren Arbeitsschritte blockiert. Das bedeutet zum Beispiel, dass wir nicht auf jeder Seite alle gleichen Skripte laden.
3. Wir lassen JavaScript, das für die initiale Darstellung der Website nicht notwendig ist, erst laden, wenn das Dokument fertig erstellt wurde. Das bedeutet auch, dass wir essenzielle Inhalte nicht über JavaScript, sondern als HTML-Inhalte bereitstellen.
Diese Punkte rücken gerade in den aktuellen Diskussionen um JavaScript und SEO oft in den Hintergrund. Frameworks, Libaries und SSR sind jedoch nachgelagerte Punkte, wenn die oben genannten bereits beachtet werden.
<!DOCTYPE html>
<html>
<head>
<meta name=”viewport” content=”width=device-width,initial-scale=1″>
<script type=”text/javascript” src=”suchbegriff-vorschlaege-produktsuche.js” ></script>
<script type=”text/javascript” src=”footer-animation.js” ></script>
<script type=”text/javascript” src=”foto-lightbox.js” ></script>
<script type=”text/javascript” src=”weitere-skripte-nachladen.js” ></script>
<link href=”style.css” rel=”stylesheet”>
<title>Unsere kleine Webseite</title>
</head>
<body>
<script type=”text/javascript” src=”ueberschriften-erstellen.js” ></script>
<p>Diese Seite hat einige Probleme. Allerdings weiß keiner so genau, welche</p>
<div><img src=”fragezeichen.jpg” class=”ohne-lightbox”></div>
<p>Was könnte es wohl sein?</p>
<script type=”text/javascript” src=”besuchererkennung.js” ></script>
</body>
</html>;
Schauen wir uns den Quelltext einer kleinen Website einmal an.
Stellen wir uns die erste Frage: Werden die Inhalte in der korrekten Reihenfolge geladen?
Nein. ganze 4 Skripte werden vor dem CSS geladen. Sie blockieren den gesamten Darstellungsprozess, können dabei noch gar nicht ausgeführt werden.
Das Skript besuchererkennung.js ist sicher wichtig, kommt aber erst ganz am Ende, steht also erstmal nicht im Weg.
Zweite Frage: Brauche ich alle diese Skripte?
Nein. Zugegeben, das Beispiel wirkt ein wenig konstruiert – verdeutlicht aber, worum es geht. Wir brauchen nicht alle Skripte. Das einzige Bild, das wir verwenden, gehört der Klasse „ohne-Lightbox“ an. Das Skript foto-lightbox.js kann demnach weggelassen werden, wir laden es umsonst. Die Skripte suchbegriff-vorschlaege-produktsuche.js und footer-animation.js sind gewiss nicht für die initiale Darstellung notwendig. Sie können geladen werden, wenn sie gebraucht werden. Das Skript weitere-skripte-nachladen.js ist ein potenzieller Pferdefuß. Nicht nur blockiert es den Darstellungsprozess, es lädt noch weitere Skripte nach. Hier muss zwingend geklärt werden, welche, warum, und ob wir darauf verzichten können.
Was wir jetzt tun:
1. Wir laden Skripte erst nach dem CSS
3. Wir entfernen unnötige Skripte
3. Wir sorgen dafür, dass die Skripte, die zur initialen Darstellung gebraucht werden, nicht dem Rendern im Weg stehen
Das sieht im Ergebnis dann wie folgt aus:
<!DOCTYPE html>
<html>
<head>
<meta name=”viewport” content=”width=device-width,initial-scale=1″>
<link href=”style.css” rel=”stylesheet”>
<script type=”text/javascript” src=”weitere-skripte-nachladen.js” defer ></script>
<title>Unsere kleine Webseite</title>
</head>
<body>
<h1>Sparsam sein mit JavaScript</h1>
<p>Diese Seite hatte einige Probleme. Allerdings konnten wir die ersten identifizieren und beheben.</p>
<div><img src=”dollarzeichen.jpg” class=”ohne-lightbox”></div>
<h2>Nach der Theorie kommt die Praxis</h2>
<p>Demnächst zeigen Wir Euch, wie wir unsere Seite optimiert haben.</p>
<script type=”text/javascript” src=”besuchererkennung.js” defer ></script>
<script type=”text/javascript” src=”footer-animation.js” defer></script>
</body>
</html>
Eine Anleitung, wie man diese und weitere Ansatzpunkte auf seiner Website identifiziert und dann genau darauf reagiert, ist bereits in Arbeit. Die Grundlagen sind jetzt zumindest geklärt.
Da fehlt doch noch was?
Richtig!
Das Skript ueberschriften-erstellen.js ähnelt dem, was bei vielen modernen JavaScript-Seiten passiert: wichtige Inhalte werden über Skripte erstellt und geladen. Die erste Devise sollte immer sein: vermeide diesen Schritt. Je weiter du JavaScript aus dem obigen Prozess heraus hältst, desto besser.
Kommen die Hinweise aus dem Zeitalter des Internet Explorers wieder? Möglich ist es
JS-Analyse: Mit diesen Werkzeugen kannst du starten
Ach, gäbe es doch alles so zahlreich wie Analyse-Tools und Softwares … Ich habe nicht vor, einen umfassenden Überblick über den gesamten Werkzeugkasten zu geben, den du einsetzen kannst. Stattdessen konzentriere ich mich auf die wenigen wichtigen Tools, für die grundlegende Ausrüstung. Mit dieser Ausrüstung kannst du starten. Ergänzungen und Erweiterungen sind so zahlreich wie Pakete im Node Package Manager (NPM) (#badnerdjoke).
Chrome
Zuallererst und am wichtigsten im Toolset ist: Chrome respektive Chromium für alle Nicht-Windows-UserInnen oder Nicht-Mac-UserInnen. Alles, was du für die Analyse-Arbeit benötigst, bringt der Browser von Haus aus mit. Ich empfehle dir, die aktuellste Version einzusetzen – oder besser gleich Chrome Canary. Denn Chrome Canary bietet oft schon Funktionalitäten, die der aktuelle Chrome noch nicht hat, und diesen Vorsprung wollen wir gerne nutzen.
Zudem benötigst du einen älteren Chrome, den wir parallel zur aktuellsten Version installieren. Google verwendet derzeit noch Chrome41 als Basis des Web Rendering Service (WRS). Daher gehört eine 41er-Version immer in deinen Werkzeugkasten – so lange bis Google den WRS aktualisiert und eine neuere Version seines Browsers einsetzt. Wir halten Augen und Ohren offen und geben Bescheid, sobald sich an dieser Baustelle etwas tut.
Add-ons/Plugins
Ich empfehle dir, ein Add-on zum Vergleichen von ungerendertem und gerendertem Quelltext zu installieren. Das ist zwar nicht zwingend erforderlich, da du beide Quelltext-Varianten auch direkt in Chrome untersuchen kannst (STRG + U öffnet den ungerenderten Ursprungsquelltext; F12 bzw. STRG + SHIFT + I zeigt dir den gerenderten Quelltext.). Ein Add-on kann es aber deutlich leichter machen, Unterschiede aufzudecken.
Add-on: View Rendered Source
Der Webdienst DiffChecker kann die gleiche Arbeit für dich übernehmen. Er ist in seiner Basisversion kostenfrei und kann Vergleiche auch speichern. Dies macht es besonders leicht, auch nach Anpassungen an der Website noch nachvollziehen zu können, welche Veränderungen wir im Blick haben wollten. Das tröstet auch über den zusätzlich notwendigen Arbeitsschritt, die Quelltext-Versionen von Hand in das Tool kopieren zu müssen.
Hinweis: Wenn du die Performance deiner Seite untersuchen möchtest, rate ich dir, einen „nackten“ Chrome zu nutzen! Einige Plugins wirken sich direkt auf die Performance aus und verfälschen damit die Ergebnisse.
Lighthouse
Lighthouse ist aktuell das Tool zur Messung von Ladezeiten und wichtigen Performance-KPIs sowie zur Ermittlung von Optimierungspotenzialen. Es gibt unterschiedliche Wege, Lighthouse einzusetzen.
Der einfachste ist, Google Chrome zu nutzen. Dieser bringt eine aktuelle Version von Lighthouse mit und ermöglicht so die direkte Analyse aller Seiten, die man mit dem Browser ansteuern kann. Das ist ideal, wenn man Seiten analysieren möchte, die nicht ohne Weiteres von externen Tools erreichbar sind. Das können zum Beispiel Entwicklungsumgebungen sein oder lokale Testanwendungen. Setzt du auf dieses Pferd, so gilt auch hier: Nutzt den „nackten“ Chrome. Außerdem ist es ratsam, Hintergrundtasks zu beenden. Wenn im Hintergrund der Frog seine Arbeit verrichtet oder dein letzter YouTube-Clip rendert, ist das Lighthouse Audit ein Fall für die Rundablage.
Die PageSpeed Insights von Google sind eine weitere Möglichkeit: Der Webdienst erfordert eine funktionierende Internet-Verbindung und kann nur Seiten analysieren, auf die er zugreifen kann. Für Entwicklungsumgebungen oder lokale Anwendungen ist er also nicht zu gebrauchen. Dafür aber für den konfigurationsfreien und ressourcenschonenden Einsatz.
Die PageSpeed Insights bieten auch eine API, über die automatisiert Daten zu Websites abgefragt werden können. Dazu im späteren Verlauf des Beitrags mehr.
Die Chrome DevTools sind die dritte Variante. Sie bieten einen leicht abgewandelten Report und die Möglichkeit, Veränderungen der Performance darzustellen. Dies ist möglich, wenn man sich mit seinem Google-Konto in dem Tool anmeldet. Da das Tool im Hintergrund lediglich das „normale“ Lighthouse ausführt, kannst du dir hier den Report im gewohnten Format anzeigen lassen.
Lighthouse ist auch als NPM-Paket verfügbar und bietet somit die Möglichkeit, auf einem eigenen Server in eigene Test-Tools eingebunden zu werden. Für die BastelfreundInnen: Ich stelle am Ende des Beitrags eine einfache Möglichkeit zur Automatisierung vor.
Mobile-Friendly Testing Tool
Ein kleines aber feines Tool zur JavaScript-Analyse bietet das Mobile-Friendly Testing Tool zur Prüfung auf Mobiltauglichkeit. Google hat dieses Werkzeug vor Kurzem in die Google Search Console integriert. Testest du eine Seite mit diesem Tool, hast du die Möglichkeit, einen Blick auf den gerenderten Quelltext der Website zu werfen. Außerdem kannst du dir Fehler und Warnungen der Konsole anzeigen lassen, die beim Rendern der Seite ausgegeben wurden.
Warum ist das erwähnenswert? Weil das Tool den gleichen Browser nutzt wie der WRS. Du kannst hier also direkt sehen, ob und womit der WRS eventuell Probleme haben könnte.
Für die Masse: JS-fähiger Crawler
Hier gibt es mittlerweile eine Reihe von Produkten am Markt, und die Möglichkeiten, sich ein eigenes Tool zu stricken, sind zahlreich.
Wenn es schnell gehen soll und der Testumfang überschaubar ist, ist der Screaming Frog SEO Spider das Tool der Wahl. Mit wenig Aufwand kann binnen kürzester Zeit ein Testcrawl angelegt und ausgewertet werden.
Wichtig: Im Screaming Frog SEO Spider werkelt ein Chrome 60! Bedenke das und teste unbedingt immer manuell mit der 41er-Version!
Die gängigen SEO- und SAAS-Lösungen bieten einen JavaScript Crawler. Allerdings solltest du hier vorher nachfragen, mit welchem Browser das Rendering erfolgt. Ideal wäre eine Chrome41-Version oder eine Eigenlösung mit der V8-Version 4.1.0, die im 41er-Chrome ihre Arbeit verrichtet.
Ein Vergleich der Quelltextvarianten ist mit dem Screaming Frog SEO Spider denkbar einfach.
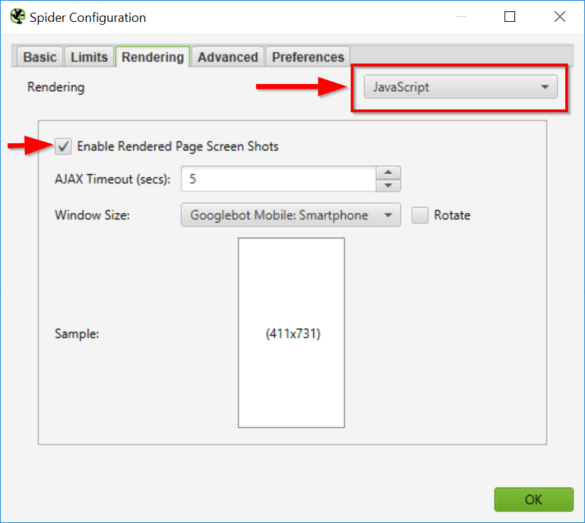
Hier aktivierst du das JS Rendering im Screaming Frog
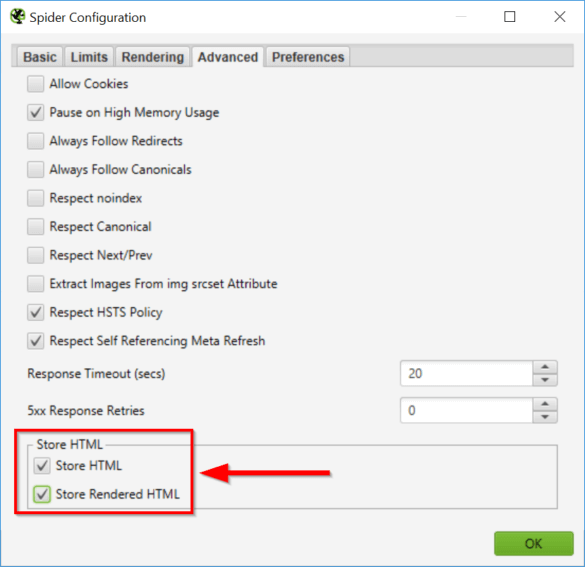
Lasse den Quelltext vor und nach dem Rendern speichern, um ihn später vergleichen zu können
Du kannst dann im Tool die Screenshots ansehen und die Quelltextvarianten vergleichen:
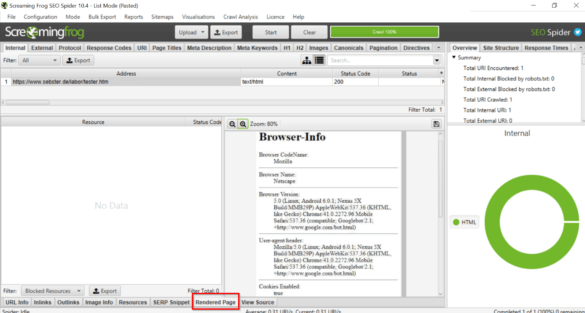
Hier siehst du den Screenshot der gerenderten Seite
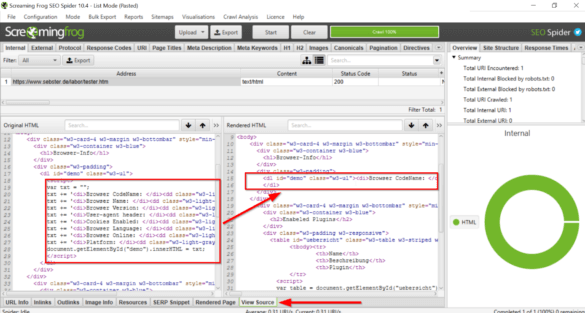
Die Quelltext-Varianten lassen sich durchsuchen – hier siehst du ein Skript und daneben das gerenderte Ergebnis des Skriptes
User Agent Strings
Mit dem User Agent String gibt sich der Client (z. B. dein Browser oder ein Crawler) gegenüber dem Server zu erkennen, von dem er ein Dokument anfordert. Diese Information wird oft genutzt, um Inhalte dynamisch auszuspielen.
Einer dieser UA-Strings, den du immer wieder brauchen wirst, ist dieser: Googlebot Mobile User Agent String.
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1;
+http://www.google.com/bot.html)
Die vollständige Liste der Bots hat Google hier bekanntgegeben: Search Console Hilfe: Google-Crawler (User-Agents).
Anwendungsfälle und Fragestellungen
Nun, da wir unseren Werkzeugkasten gepackt haben, können wir uns die Fragen ansehen, die wir damit bearbeiten können.
Lege vor den Untersuchungen fest, welche Inhalte auf welcher Seite wirklich wichtig sind und vorhanden sein müssen. Mache dir am besten eine Liste, die du abarbeiten kannst.
Zu den Inhalten, die unbedingt vorhanden sein und funktionieren müssen, gehören zum Beispiel:
Die erste und einfachste Frage lautet:
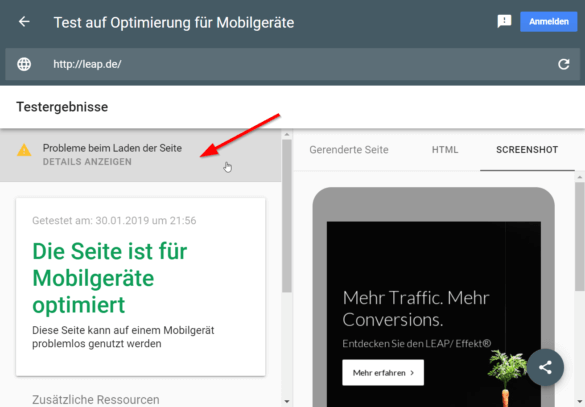
„Hat Google Probleme beim Rendern meiner Seite?“
Ist die Seite bereits live, kannst du das Mobile-Friendly Testing Tool nutzen.
Die folgenden drei Punkte sind besonders wichtig:
1. Entspricht der Screenshot deinen Erwartungen oder fehlt etwas Wichtiges?
2. Sind im Quelltext alle Inhalte, die indexiert werden sollen, zu finden? (Am besten kopierst du den Quelltext aus dem Tool und untersuchst diesen in einem separaten Editor.)
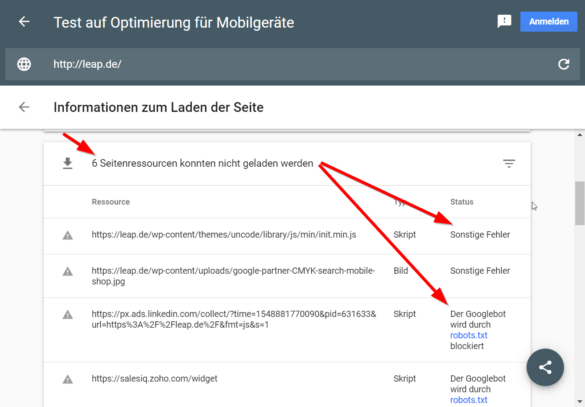
3. Schaue unbedingt in die Hinweise zu den Ressourcen und in die JavaScript-Fehlerkonsole!
Der Screenshot gibt dir einen ersten Eindruck, wie Google die Seite „sieht“. Er dient jedoch nur als Hinweisgeber, zumal er nicht scrollbar ist und wichtige Inhalte „below the fold“ versteckt sein können.
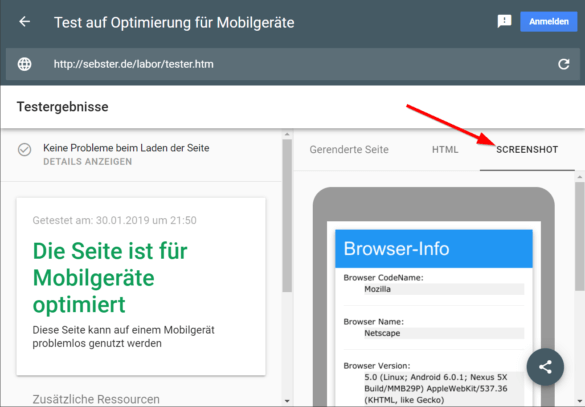
Der Screenshot der gerenderten Seite ermöglicht einen ersten Überblick
Der Quelltext ist die Referenz zum Testen. Kopiere ihn und vergleiche ihn mit dem Quelltext der gerenderten Seite aus eine aktuellen Browser. Hier können erste Unterschiede auftreten, denen du nachgehen musst.
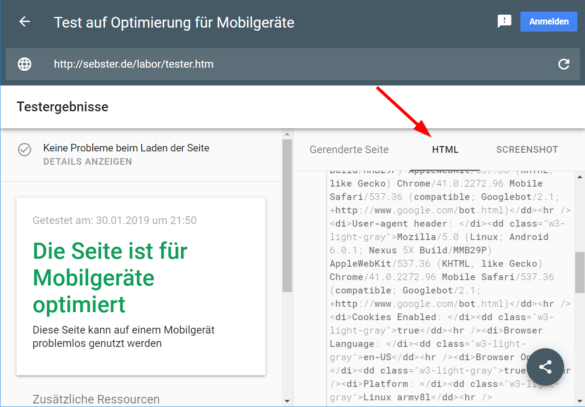
Das Tool zeigt auch den gerenderten Quelltext
Fehlen auf dem Screenshot oder im Quelltext wichtige Inhalte, musst du mit deinen Entwicklern oder Entwicklerinnen klären, auf welchem Weg diese auf die Seite gelangen und woran es liegen könnte, dass sie in Chrome41 nicht auftauchen. So könnte es zum Beispiel sein, dass die Komponente, die den fehlenden Seiteninhalt darstellen soll, eine Funktion verwendet, die von Chrome41 nicht unterstützt wird, oder dass das JavaScript bereits vor dem Laden der entsprechenden Komponente mit einem Fehler abbricht.
Prüfe in der Ressourcen-Meldung, ob alle wichtigen Ressourcen geladen werden können. Dazu gehören CSS-Dateien und JS-Dateien, die für die initiale Darstellung der Seite notwendig sind.
Screenshot Mobile-Friendly Testing Tool
Screenshot Mobile-Friendly Testing Tool
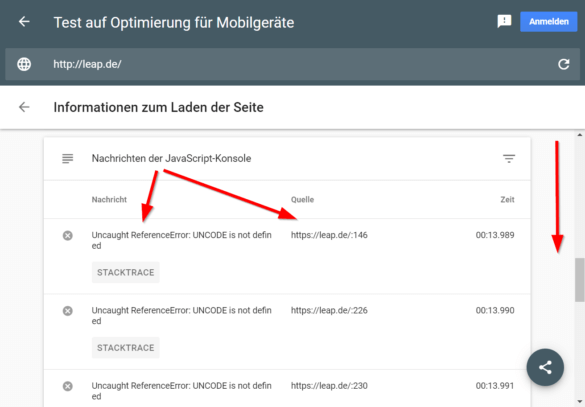
Zuletzt schaue etwas weiter unten in der JavaScript-Konsole unter den Ressourcen. Fehler, die hier auftauchen, klärst du am besten mit deinem Entwicklungsteam ab. Nicht jede Warnung und jeder Fehler ist kritisch. Je nachdem, wie tief du in der Technik deines Projekts steckst, kannst du das auch selbst beurteilen. Das Zwei-Augen-Prinzip hat sich für mich jedoch stets bewährt.
Das Tool zeigt Ressourcen, die nicht geladen werden konnten – nicht alle davon sind zwingend notwendig
Ist deine Seite nicht von außen erreichbar, kannst du den Chrome41 nutzen. Stelle als Device „Nexus 5“ und als Network „3G“ ein. Dies kommt den Testkriterien von Google am nächsten. Durch die Simulation von 3G erhältst du gleich ein Gefühl für die Seiten-Performance.

Die Device Emulation in den Chrome Dev-Tools
Du siehst auch: Unterhalb der Netzwerk-Einstellungen kannst du den UA-String verändern, mit dem sich der Browser beim Testen beim Server meldet.
Mit diesen Einstellungen rufst du die betreffende Seite auf und prüfst zuerst, ob alles so aussieht und funktioniert, wie es soll:
Prüfe zuerst, ob alle Inhalte sichtbar sind, die du erwartest. Wirf dann einen Blick in den gerenderten Quelltext (F12). Hier kannst du auch die Auszeichnungen mit strukturierten Daten oder die Metadaten überprüfen. Danach kannst du schauen, ob all diese Dinge auch im initial ausgelieferten Quelltext stimmen (STRG+U).
Hier ist es besonders wichtig, dass Auszeichnungen oder Canonicals enthalten sind.
Dann konsultierst du die Konsole des Browsers:
Fehler und Warnungen liefern dann wieder Anlass zur Klärung mit dem Dev-Team
Änderungen oder Neuentwicklungen an der Website testen
Oft werden neue Features, Module und Seitenelemente für aktuelle Browser entwickelt. Daran ist nichts Falsches – solange die Abwärtskompatibilität gewährleistet ist. So stellst du sicher, dass deine Website mit dem Google WRS kompatibel ist.
Das Wichtigste ohne JS liefern
Generell gilt die Faustregel: Wenn ein Inhalt ranken soll, ist es am sichersten, ihn als Plain-HTML auszuliefern. Punkt. Die Diskussion, ob Google JS ausführen kann und dabei auch schon sehr erfolgreich ist, blendet einen wichtigen Faktor aus: den Aufwand, den wir Google mit JS-lastigen Inhalten aufhalsen.
Daher lege Wert darauf, die wichtigsten Inhalte ganz klassisch auszuliefern. Das ist vielleicht nicht das Aufregendste, aber dafür gehst du auf Nummer sicher.
Der erste Test gilt daher der Seite ohne aktiviertes JavaScript: Dazu öffnest du die Dev-Tools mit F12 und dann die Einstellungen mit F1. Du deaktivierst den Browser-Cache (das simuliert den ersten Besuch auf der Seite) und JavaScript (das zeigt dir die Seite, wie sie dem Googlebot geliefert wird).
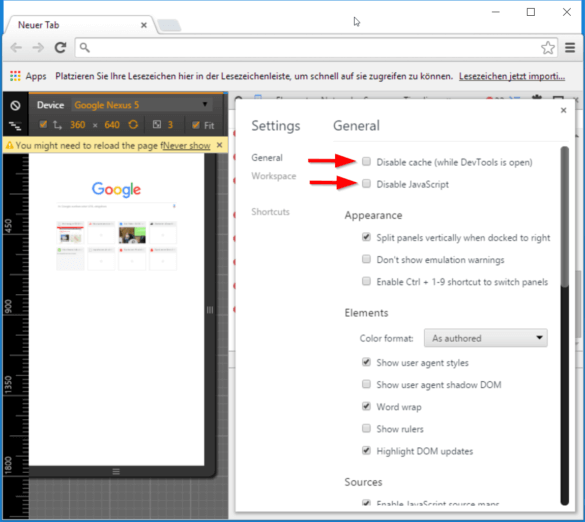
Hier deaktivierst du JavaScript und den lokalen Cache in Chrome41
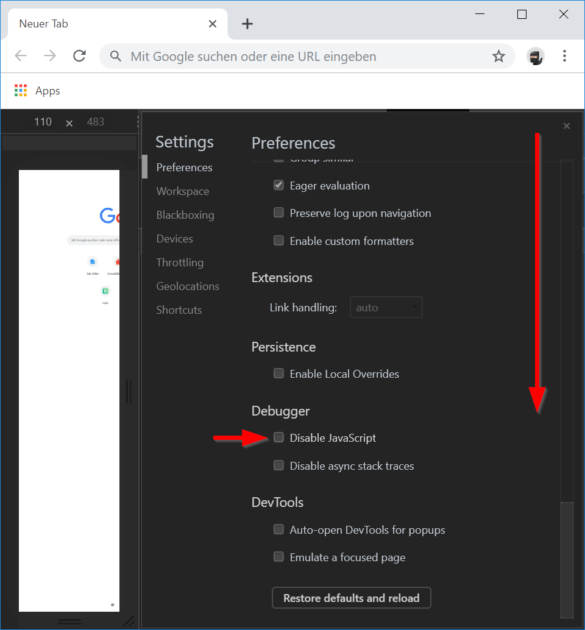
In aktuellen Chrome-Versionen sind die Einstellungen etwas anders sortiert
Jetzt wird es spannend: Sind alle SEO-relevanten Inhalte da? Ist das neue Feature sichtbar? Es ist überhaupt nicht schlimm, wenn die Seite etwas seltsam aussieht oder sich nicht haargenau so verhält wie unter echten Bedingungen. Ohne JavaScript funktionieren oft die Menüs nicht, oder statt der Grafiken werden nur kleine Lade-Symbole gezeigt.
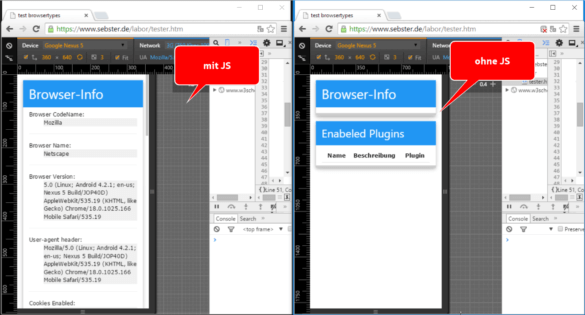
Die Inhalte dieser Seite sind komplett von JavaScript abhängig – das kann zum Problem werden
Wichtig ist aber, dass du die oben definierten Inhalte finden kannst. Alles, was die Suchmaschine bei der Bewertung dieser Einzelseite berücksichtigen soll, sollte jetzt vorhanden sein.
Auch ein Blick in den Quelltext darf nicht fehlen, denn du prüfst auch die Meta-Daten.
Tipp: Mache einen Screenshot der Seite und kopiere den Quelltext für den Abgleich mit der Darstellung mit aktiviertem JavaScript.
Nach der Bestandsaufnahme ohne JS machst du den gleichen Test mit JS. Inspiziere die Darstellung. Schaue in den Quellcode. Und ganz wichtig: Schaue auch in die Konsole!
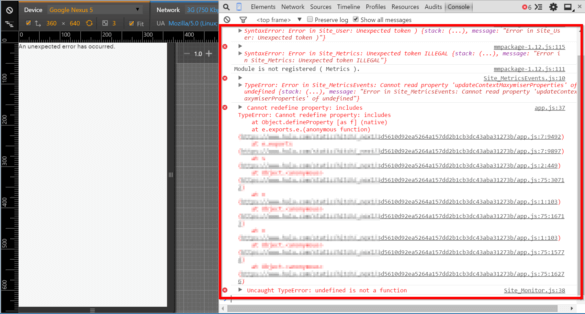
Beispiel eines Extremfalls: Hier kann Chrome41 das JavaScript nicht sinnvoll nutzen
Wenn dich die Fehlermeldungen ratlos zurücklassen – kein Problem: Deine Entwickler können dir helfen! Steckst du tiefer in der Materie, kannst du mit einem Klick auf die Referenz neben der Fehlermeldung direkt an die Stelle im Quellcode des Skriptes springen, an der der Fehler aufgetreten ist. Analysiere dabei am besten immer von unten nach oben. Also von der letzten bis zur ersten Fehlermeldung.
Wird die Seite korrekt dargestellt, vergleichst du den gerenderten Quelltext mit dem Quelltext aus dem letzten Test und prüfst, ob sich SEO-relevante Inhalte verändert haben. Ist etwa ein <title> hinzugekommen oder der Canonical verschwunden, dann wird es Zeit zu handeln.
Nicht auf JavaScript angewiesene Inhalte
Zugegeben, oft geht es schon gar nicht mehr ohne JavaScript. Und das ist auch in Ordnung. Moderne Frameworks und Libraries bieten Möglichkeiten, die „konventionelle“ Entwicklung nicht hat. Du solltest jedoch immer auf weitestgehende Abwärtskompatibilität achten!
Sprich mit dem Dev-Team, welche Technologien eingesetzt werden und prüfe, ob sie vom WRS unterstützt werden. Suche Alternativen oder Anpassungen, wo es nötig ist. Es muss nicht jedes Feature oder Detail angepasst werden. Die SEO-relevanten Inhalte müssen aber immer auf optimales Rendering ausgerichtet sein.
Eine Übersicht über die Features, die Browser unterstützen, bietet CANIUSE Chrome41.
Es gibt immer eine Möglichkeit, Abwärtskompatibilität herzustellen. Setzt du deine Entwicklung auf modernste ES6-Syntax, können sie mit Babel dafür sorgen, dass der Code in „ältere“ Formen übersetzt und so für ältere Browser verständlich wird. Sogenannte Polyfills sorgen dafür, Features, die moderne Browser bieten, für ältere Versionen „nachzubilden“. Alleine schon hierzu könnten wir einen gesonderten Artikel schreiben. Deine Entwickler und Entwicklerinnen werden sich damit aber in der Regel schon auskennen.
Sonderfall Prerenderer und Dynamic Serving
Wenn du dich mit Googles-Anleitungen und Empfehlungen zum Thema JS-SEO befässt, kommst du am Thema Dynamic Serving nicht vorbei.
Im Großen und Ganzen bedeutet Dynamic Serving, dass du deine Seite in einem anderen Zustand an den Googlebot auslieferst als an deine menschlichen UserInnen. Ruft ein User oder eine Userin deine Seite auf, erhält er bzw. sie die JavaScript-lastige Seite mit vielen dynamischen Inhalten ausgeliefert. Ruft der Googlebot deine Seite auf, liefert der Server diesem jedoch anstelle der JavaScript-lastigen Seite eine (weitestgehend) statische Seite aus. Diese statische Seite wird von einem Prerenderer erstellt und in der Regel nach der Erstellung in einem Cache zwischengespeichert, um zu häufiges Vorrendern zu vermeiden. Hier liegt auch ein großer Knackpunkt der Lösung: die Vorhaltezeit der statischen Seiten. Weitere Informationen dazu findest du bei Google.
Damit das Konzept funktioniert, ist wichtig, dass der Server den Bot auch richtig erkennt. Teste die Erkennung, indem du den User Agent in den Dev-Tools änderst. Probiere auch mal Abwandlungen der UA-Strings aus, um zu sehen, ob die Erkennung nicht eventuell über einen abgeänderten UA-String stolpert.
Ist die Seite bereits live, kannst du wie oben beschrieben mit dem Mobile-Friendly Test von Google einsteigen. Zeigt das Tool die Seite und den Quelltext wie erwartet, ist das System korrekt eingerichtet. Stimmt irgendwas nicht, geht‘s mit den Browsertests weiter. Auch Entwicklungsumgebungen testest du wie oben beschrieben in Chrome41 mit und ohne JavaScript, einmal mit einem generischen User Agent und einmal mit dem Googlebot-User-Agent. Du prüfst wieder auf die SEO-relevanten Elemente.
Hinzu kommt diesmal ein zusätzlicher Test: Sind zeitabhängige Inhalte auch aktuell? Durch das Caching der vorgerenderten Inhalte kann es nämlich dazu kommen, dass es zu empfindlichen Unterschieden in den Varianten kommt.
Ein Beispiel hierfür sind Aktionsbanner oder Aktionspreise.
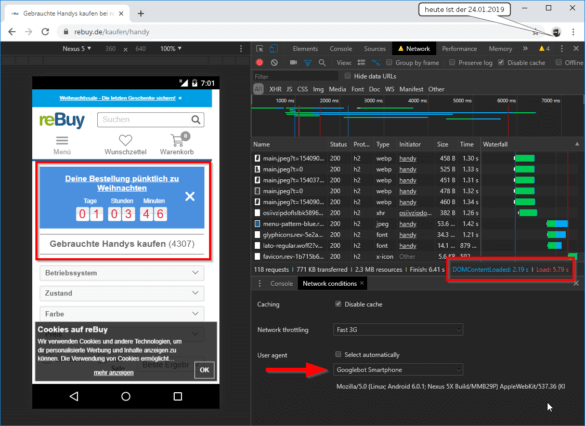
Dieses Beispiel ist nicht unbedingt kritisch, zeigt aber zu welchen Abweichungen es kommen kann
Bedenke: Dynamic Serving ist ein Workaround und eine Lösung für hochdynamische und komplexe Inhalte, wie Social Media Streams oder Seiten, die mit Echtzeit-Daten arbeiten. Es ist nicht der goldene Weg für die Auslieferung einer Produktübersichtsseite, deren Inhalt sich einmal in der Woche ändern kann.
Ladezeiten und blockierende Skripte
PageSpeed ist ein Thema für sich. Oft ist jedoch JavaScript mitverantwortlich für zu lange Ladezeiten. Das Tool für Ladezeiten-Tests ist Lighthouse. Lighthouse ist mittlerweile die Basis der PageSpeed Insights sowie als eigenständiges Tool online verfügbar. Für Tests auf Staging-Systemen ist das Tool seit längerer Zeit auch Teil der Chrome DevTools. Die Ergebnisseiten der Tools sehen leicht unterschiedlich aus, weisen aber alle die gleichen Erkenntnisse und Empfehlungen aus.
Öffne in Chrome (diesmal bitte die aktuellste Version, da ältere Versionen nicht die aktuellsten Lighthouse-Versionen mit sich bringen) die DevTools mit F12. Unter „Audits“ findest du die Konfigurationsseite von Lighthouse.
Dort stellst du auf „Mobile Device“ (Mobile first!), wählst die Audits („Performance“ ist für uns jetzt am interessantesten) und „Applied Fast 3G“ (Netzwerkgeschwindigkeit drosseln). Danach einfach auf „Run Audits“ klicken, und nach ein paar Sekunden steht der Report zur Verfügung. Während des Tests versorgt dich das Tool mit nützlichen Tipps rund um PageSpeed Mobile Friendliness.
Der Report schlüsselt diverse Erkenntnisse auf:
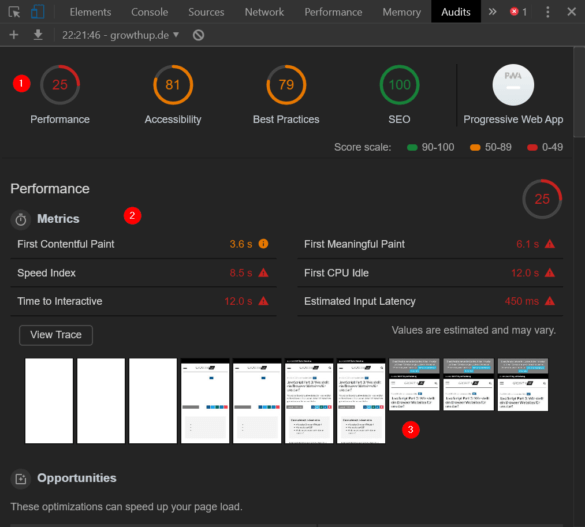
Der Lighthouse Report in den DevTools
Du bekommst:
1. Performance Scores zu Vergleichbarkeit von Tests
2. Detailliertere Metriken inkl. einer optisch erkennbaren Dringlichkeitseinschätzung
3. Screenshots, die den Rendering-Prozess verdeutlichen
Etwas weiter unten siehst du dann die Opportunities:
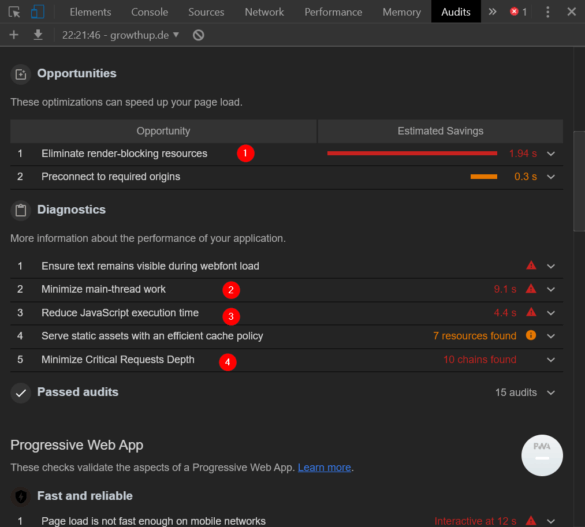
Lighthouse zeigt wichtige Maßnahmen, die die Performance verbessern
In den meisten Fällen steckt JavaScript hinter folgenden Punkten:
1. Rendering-blockierende Ressourcen minimieren (JavaScript kann das Rendering blockieren)
2. Main Thread Work reduzieren (zu umfangreiches JavaScript kostet viel Rechenpower)
3. JavaScript-Ausführungszeit reduzieren (bei komplexen Skripten kümmert sich der Browser oftmals länger um das JS als notwendig)
4. Kritische Request-Ketten minimieren (oft rufen einzelne Skripte wieder andere Skripte auf und laden Inhalte nach, wodurch viele Anfrage-Ketten entstehen)
Ursachen und Lösungen hierfür kennen deine Devs. Wenn du die Ergebnisse teilen möchtest, bietet das Tool auch den Export der Testergebnisse an.
Lighthouse ist mittlerweile sehr beliebt, um Tests zu automatisieren und über viele Seiten hinweg Fehler einzugrenzen oder die Performance von Websites zu überwachen.
Wenn du wissen möchtest, ob auf allen URLs deiner Website die gleichen Probleme bestehen, kannst du Lighthouse auch im Autopilot betreiben. Eine Anleitung dazu gibt es beim Technical SEO Strategist Mike Osolinski, eine Ergänzung für die PowerShell habe ich mal nachgeliefert.

Lighthouse im Autopilot ist übrigens auf einem Server besser aufgehoben als auf einem Desktop/Laptop. Daher: Zum Probieren und schnellen Nachgucken ist die Lösung gangbar. Für Monitoring eher nicht.
Natürlich kann man auch mit SEOs Lieblingstool Excel arbeiten. Die SEO-Tools for Excel haben einen Connector zu den PageSpeed Insights. Dieser zapft die Web API der PageSpeed Insights an und liefert auch ohne Node.js und Shellskript schnell Daten zum Auswerten und Weiterschicken. So wird es zum Beispiel zum Kinderspiel, einen flotten Audit seiner Sitemap zu erstellen.
Da wir gerade beim Performance-Messung sind: Beim nächsten Mal schauen wir uns an, wie wir die Performance genauer untersuchen können. Denn die Darstellung alleine ist nicht alles: Schnell sollte es natürlich auch gehen.
Fazit
Mach dir klar, welche Inhalte du für gutes SEO auf deiner Seite benötigst, und fertige eine Checkliste für die Tests an. Teste immer sowohl mit einer alten als auch mit einer aktuellen Chrome-Version – immer mit und ohne JavaScript-Ausführung. Damit stellst du sicher, dass der Google Web Rendering Service mit deiner Seite umgehen kann. Arbeite darauf hin, wichtige SEO-Inhalte ohne JavaScript auszuliefern und schließe dich mit deinem Dev-Teams kurz, um Fehler und Auffälligkeiten in der Darstellung zu klären.



